Лекция 3
Ранние СУБД - системы, основанные на инвертированных списках, иерархические и сетевые СУБД
Лекция посвящена рассмотрению различных подходов к организации баз данных.
Следует сразу заметить, что описанные ниже системы при всех различиях имеют много общего: так, например, данные в (некоторых из) них организованы в виде таблиц. Вообще говоря, таблица – очевидно, естественный способ организации множества однородных записей. Строки в таких таблицах представляют собой записи об отдельных сущностях. Для упрощения дальнейшего изложения следует описать несколько дополнительных базовых понятий.
Ключом называют совокупность полей записи или столбцов таблицы, идентифицирующую экземпляры данных или определяющую их свойство, используемое при управлении/обработке данных. Ключи используются для идентификации записей или строк таблиц, задании критерия поиска, группирования, сортировки, индексирования, определения места размещения и поиска методом хеширования, управления доступом и т.д. Существуют как уникальные (<= 1 значения для заданного значения ключа), так и неуникальные ключи. Понятие “ключ” применительно к СУБД сильно загружено, поэтому всегда стоит внимательно следить за тем, о каких именно типах ключей идёт речь.
Индексом называют вспомогательную структуру БД, используемую для повышения производительности поиска операций данных по заданному критерию, обеспечения обработки данных в соответствии с порядком значений ключа или вычисления различных статистических характеристик, зависящих только лишь от значения ключей. Организация индексов – вопрос конкретной реализации. Создание индексов подразумевает выделение дополнительной памяти, а также дополнительные вычислительные расходы на поддержание соответствия индекса и данных при модификации данных.
Системы, предшествовавшие появлению доминирующих в настоящее время реляционных СУБД (РСУБД) и оказавшие на РСУБД значительное влияние.
Полезная информация:
- Эти системы использовались значительное время.
- Они не были основаны на какой-либо абстрактной модели данных (модели данных для них появились позже самих систем).
Доступ осуществлялся на уровне записей с явной навигацией по записям на уровне пользователя.
Системы, основанные на инвертированных списках
Инвертированный список – это организованный в вид списка специального вида вторичный индекс, то есть индекс файла (или, как мы сказали ранее, таблицы), по вторичному (то есть неуникальному) ключу, позволяющий получить всю совокупность указателей на элементы данных (записи), которым соответствует заданное значение ключа индексации. (физическая организация ИС – см. напр. Д. Кнут, “Искусство программирования”, том 3. Сортировка и поиск – стр. 605, 608)
Организация доступа к данным на основе инвертированных списков используется практически во всех современных реляционных СУБД, но в этих системах пользователи не имеют непосредственного доступа к инвертированным спискам (индексам).
Структуры данных
База данных, организованная с помощью инвертированных списков, похожа на реляционную БД, но с тем отличием, что хранимые таблицы и пути доступа к ним видны пользователям. При этом:
- Строки таблиц упорядочены системой в некоторой физической последовательности.
- Физическая упорядоченность строк всех таблиц может определяться и для всей БД
- Для каждой таблицы можно определить произвольное число ключей поиска, для которых строятся индексы. Эти индексы автоматически поддерживаются системой, но явно видны пользователям.
Манипулирование данными
Поддерживаются два класса операторов:
Операторы, устанавливающие адрес записи, среди которых:
- прямые поисковые операторы (например, найти первую запись таблицы по некоторому пути доступа);
- операторы, находящие запись в терминах относительной позиции от предыдущей записи по некоторому пути доступа.
Операторы над адресуемыми записями.
Типичный набор операторов:
- LOCATE FIRST - найти первую запись таблицы T в физическом порядке; возвращает адрес записи;
- LOCATE FIRST WITH SEARCH KEY EQUAL - найти первую запись таблицы T с заданным значением ключа поиска K; возвращает адрес записи;
- LOCATE NEXT - найти первую запись, следующую за записью с заданным адресом в заданном пути доступа; возвращает адрес записи;
- LOCATE NEXT WITH SEARCH KEY EQUAL - найти cледующую запись таблицы T в порядке пути поиска с заданным значением K; должно быть соответствие между используемым способом сканирования и ключом K; возвращает адрес записи;
- LOCATE FIRST WITH SEARCH KEY GREATER - найти первую запись таблицы T в порядке ключа поиска K cо значением ключевого поля, большим заданного значения K; возвращает адрес записи;
- RETRIVE - выбрать запись с указанным адресом;
- UPDATE - обновить запись с указанным адресом;
- DELETE - удалить запись с указанным адресом;
- STORE - включить запись в указанную таблицу; операция генерирует адрес записи.
Ограничения целостности
Общие правила определения целостности БД отсутствуют. В некоторых системах поддерживаются ограничения уникальности значений некоторых полей, но в основном все возлагается на прикладную программу.
Иерархические системы
Иерархическая БД состоит из упорядоченного набора деревьев; более точно, из упорядоченного набора нескольких экземпляров одного типа дерева (ср. классы и экземпляры классов в объектно-ориентированном программировании).
Тип дерева состоит из одного "корневого" типа записи и упорядоченного набора из нуля или более типов поддеревьев (каждое из которых является некоторым типом дерева) – ср. с наследованием в ООП. Тип дерева в целом представляет собой иерархически организованный набор типов записи.
Пример типа дерева (схемы иерархической БД):
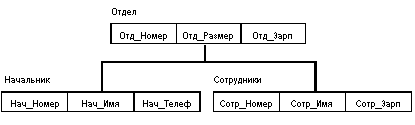
Здесь Отдел является предком для Начальник и Сотрудники, а Начальник и Сотрудники - потомки Отдел. Между типами записи поддерживаются связи.
База данных с такой схемой могла бы выглядеть следующим образом (мы показываем один экземпляр дерева, но следует помнить, что в БД хранится некое множество экземпляров):
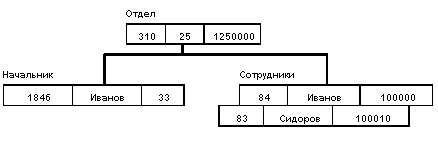
Все экземпляры данного типа потомка с общим экземпляром типа предка называются близнецами (например, показанные выше экземпляры записей о сотрудниках). Для БД определен полный порядок обхода - сверху-вниз, слева-направо.
Манипулирование данными
Примерами типичных операторов манипулирования иерархически организованными данными могут быть следующие:
- Найти указанное дерево БД (например, отдел 310);
- Перейти от одного дерева к другому;
- Перейти от одной записи к другой внутри дерева (например, от отдела - к первому сотруднику);
- Перейти от одной записи к другой в порядке обхода иерархии (перейти к следующему сотруднику - второму);
- Вставить новую запись в указанную позицию (добавить сотрудника после второго);
Ограничения целостности
Автоматически поддерживается целостность ссылок между предками и потомками. Основное правило: никакой потомок не может существовать без своего родителя. Заметим, что аналогичное поддержание целостности по ссылкам между записями, не входящими в одну иерархию, не поддерживается (примером такой "внешней" ссылки может быть содержимое поля Каф_Номер в экземпляре типа записи Куратор).
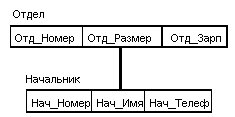
В иерархических системах поддерживалась некоторая форма представлений (views, см. Лекцию 2) БД на основе ограничения иерархии. Примером представления приведенной выше БД может быть иерархия
Сетевые системы
Сетевые структуры данных
Сетевой подход к организации данных является расширением иерархического. В иерархических структурах запись-потомок должна иметь в точности одного предка; в сетевой структуре данных потомок может иметь любое число предков.
Сетевая БД состоит из набора записей и набора связей между этими записями, а если говорить более точно, из набора экземпляров каждого типа из заданного в схеме БД набора типов записи и набора экземпляров каждого типа из заданного набора типов связи.
Тип связи определяется для двух типов записи: предка и потомка. Экземпляр типа связи состоит из одного экземпляра типа записи предка и упорядоченного набора экземпляров типа записи потомка. Для данного типа связи L с типом записи предка P и типом записи потомка C должны выполняться следующие два условия:
- Каждый экземпляр типа P является предком только в одном экземпляре L;
- Каждый экземпляр C является потомком не более, чем в одном экземпляре L.
На формирование типов связи не накладываются особые ограничения; возможны, например, следующие ситуации:
- Тип записи потомка в одном типе связи L1 может быть типом записи предка в другом типе связи L2 (как в иерархии).
- Данный тип записи P может быть типом записи предка в любом числе типов связи.
- Данный тип записи P может быть типом записи потомка в любом числе типов связи.
- Может существовать любое число типов связи с одним и тем же типом записи предка и одним и тем же типом записи потомка; и если L1 и L2 - два типа связи с одним и тем же типом записи предка P и одним и тем же типом записи потомка C, то правила, по которым образуется родство, в разных связях могут различаться.
- Типы записи X и Y могут быть предком и потомком в одной связи и потомком и предком - в другой.
- Предок и потомок могут быть одного типа записи.
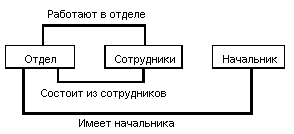
Простой пример сетевой схемы БД:
Манипулирование данными
Примерный набор операций может быть следующим:
- Найти конкретную запись в наборе однотипных записей (инженера Сидорова);
- Перейти от предка к первому потомку по некоторой связи (к первому сотруднику отдела 310);
- Перейти к следующему потомку в некоторой связи (от Сидорова к Иванову);
- Перейти от потомка к предку по некоторой связи (найти отдел Сидорова);
- Создать новую запись;
- Уничтожить запись;
- Модифицировать запись;
- Включить в связь;
- Исключить из связи;
Переставить в другую связь и т.д.
Ограничения целостности
В принципе их поддержание не требуется, но иногда требуют целостности по ссылкам (как в иерархической модели).
Достоинства и недостатки
Сильные места ранних СУБД:
- Развитые средства управления данными во внешней памяти на низком уровне;
- Возможность построения вручную эффективных прикладных систем;
- Возможность экономии памяти за счет разделения подобъектов (в сетевых системах).
Недостатки:
- Слишком сложно пользоваться;
- Фактически необходимы знания о физической организации;
- Прикладные системы зависят от этой организации;
- Их логика перегружена деталями организации доступа к БД.
|
